Reading the unreadable: an AI study of the Voynich Manuscript
What disciplined, AI-directed analysis can — and cannot — tell us about one of the world's most famous undeciphered books.
The Voynich Manuscript is a ~240-page illustrated codex, carbon-dated to the early 1400s, written in a script no one has verifiably read. We did not decipher it — and this page is honest about that from the first line. What we did instead was treat it as a data problem: build an analysis pipeline, reproduce the structural facts the field already knows, test the popular theories against statistical controls, and map the exact point where structure stops and meaning begins.
What this study did NOT do. No decipherment. No translation. No new cipher "cracked." Most of the headline findings below reproduce results already published in the Voynich literature — that was the point of the validation step, not a discovery. The value here is the method and its honesty, not a breakthrough. A study that tells you precisely what AI can't resolve is worth more than one that pretends to solve a 600-year-old mystery.
The one-paragraph result
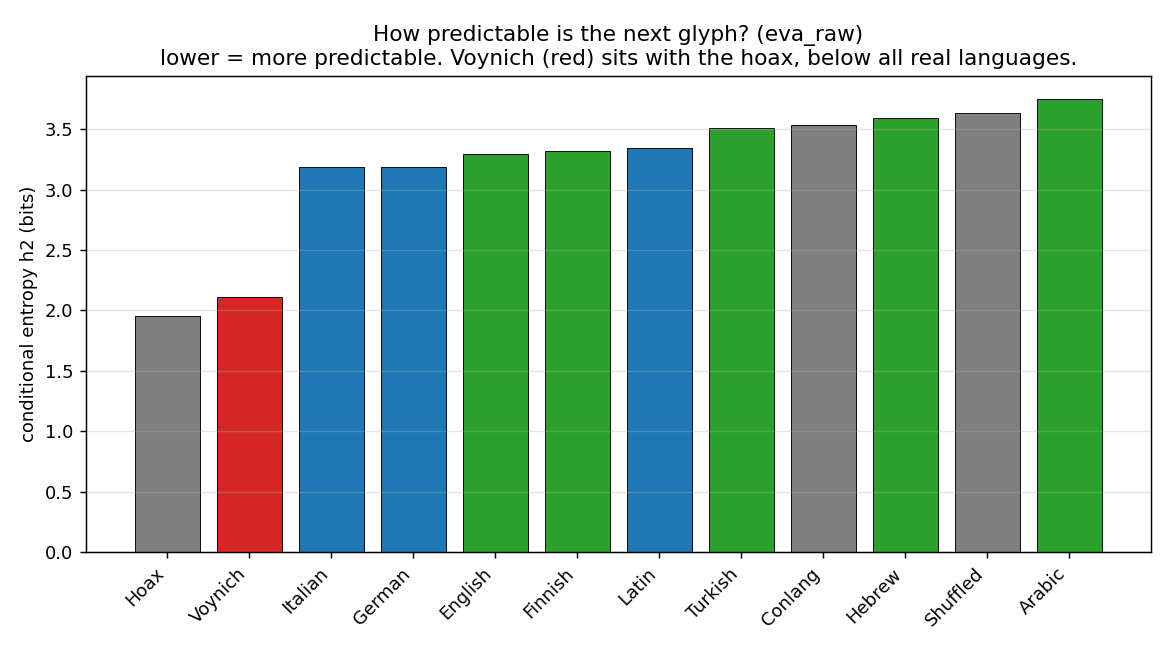
Structurally, the manuscript behaves like a single constructed, templated writing system — words built from a rigid positional "slot-grammar" that is the same across the manuscript's two known variants. It looks like language on whole-text statistics (Zipf's law, vocabulary growth) yet not on local ones (its glyph-to-glyph entropy is lower than any natural language and matches only a meaningless generator). Its architecture is "strong word-structure, weak word-order" — a labelled, topic-organized catalogue, not flowing prose. Whether that template carries real meaning or is the output of a structured generative process is the one question the analysis leaves open — because the deciding evidence is invisible to structural statistics.
What the analysis actually shows
| Finding | Status |
|---|---|
| Low glyph-to-glyph entropy; rigid positional slot-grammar; Zipf's law; tight word lengths | reproduced known results |
| Vocabulary is organized by topic (content words cluster by section) | reproduced (Montemurro & Zanette, 2013) |
| Best-fitting model is a constructed slot-grammar, beating real languages and a hoax | supported |
| Decoy "null" glyphs · reading-direction tricks · language-blending · simple ciphers · simple uniform gibberish · star pages as sky maps | ruled out with controls |
| Does it carry linguistic meaning, or is it a structured generator? | open — beyond what structure can decide |
All 33 Python modules, the test suite, and the full write-ups. No data is bundled — the scripts fetch it from public sources and reproduce every figure with one command. (Image-analysis additions are planned and will be added here as the project's computer-vision phase proceeds.)
Read deeper
What we established (and that it reproduces known work)
The pipeline first had to earn trust by reproducing facts established independently in
the literature — and it did: the anomalously low conditional entropy, Zipf's law, the
tight ~5-glyph word-length peak, and the rigid positionality (the glyph q
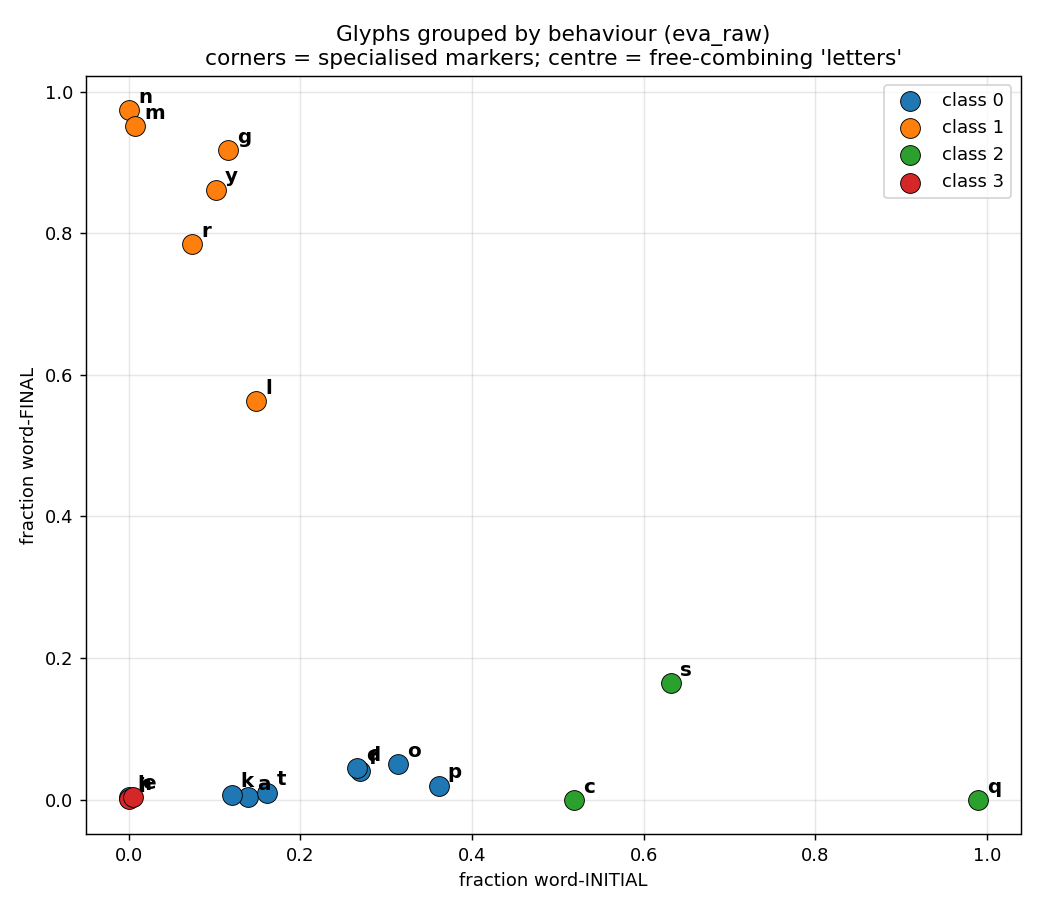
begins 99% of its words; n ends 97%). It then found that the glyphs fall into
four functional classes, that words are unusually combinatorial (systematic variations on
shared skeletons), and that a compact constructed slot-grammar models the text
better than any natural language or a hoax generator.
What we ruled out — and why "ruled out" is the real product
Arguably the most defensible output of the project is a set of popular ideas eliminated with a control rather than an opinion: decoy "null" glyphs (deleting them does not recover language-like structure); reading-direction tricks (boustrophedon makes it worse; plain reversal is mathematically undecidable); language-blending (the entropy is below every language we tested, and averaging can't get there); simple substitution/verbose ciphers; simple uniform mechanical gibberish (a topic-blind generator produces zero topic structure — the real text has it); and the star pages as positional sky maps (their stars are arranged far too regularly, and contain no cluster to match).
None of these were novel doubts — the field already leaned this way. The contribution is that each was tested and reported honestly, including the clean negatives.
The one thing structure fundamentally can't resolve
A finite reused vocabulary (meaning) and a self-citation/copy-and-tweak generator (mechanism) produce identical statistics — same entropy, same vocabulary growth, same word-shape. We confirmed this against a fair adversary: a richly-built meaningless generator, matched to the manuscript's own vocabulary, lands closer to the Voynich than any real language. And a substitution — each glyph standing for a letter — is invisible to these structural statistics, so the analysis cannot even name the underlying language. Reading the manuscript would require a crib (a known word, perhaps from a labelled drawing) — outside evidence that the text alone will not give up. That boundary is a result in itself.
How it was done — directing AI
The investigation ran as a sequence of falsifiable hypotheses, each a response to the last result, decided by evidence rather than preference. The human role was to frame the problem, generate and order the hypotheses, and insist on the right control for each claim — overfitting guards, shuffle nulls, within-group confound controls, reproductions of known figures. The AI built and ran the pipeline. Several hypotheses were allowed to be falsified, which is the clearest sign the process sought truth rather than confirmation. As a demonstration of applied AI, the takeaway is the discipline: AI as a force multiplier for rigorous analysis, with a human keeping it honest.
Data, code & reproducibility
The downloadable bundle contains the complete pipeline (33 modules), a passing test suite that checks the results reproduce known corpus figures, and the full write-ups (a finding-by-finding log and a calibrated synthesis). It bundles no data; an acquisition script fetches everything from public, openly-licensed sources and regenerates every figure with one command.
Sources: Voynich transliteration (voynich.nu, ZL/IVTFF) · page scans (Beinecke Library, Yale, public domain, IIIF) · per-word coordinates (voynichese.com, Apache-2.0) · reference-language corpora (Tatoeba) · star catalogue (HYG database). Data is fetched, not redistributed.
An honesty statement
This project did not solve the Voynich Manuscript, and it did not discover much the field did not already know. It reproduced the manuscript's known structure, eliminated several popular theories with controls, reached a calibrated description — a constructed, topic-organized, catalogue-like writing system — and identified precisely where the evidence runs out. We publish it as an example of how the Saelix AI Lab approaches hard problems: hypothesis-driven, control-backed, and unwilling to claim more than the evidence earns. In a field littered with confident "solutions," a bounded and falsifiable answer — including its negatives — is the result worth standing behind.